Open source isn't a business model. It's a distribution superpower.
Think about it: millions of developers trying your product, giving feedback, building alongside you—all without a single sales call. But here's the catch that trips up most companies: turning that organic developer love into actual revenue requires serious work. And it starts with answering a deceptively simple question: which developers, in which organizations, are using your open source project with real business intent behind their exploration?
Cracking this puzzle unlocks massive value for commercial open source businesses. Enterprise sales teams armed with this intelligence know exactly which accounts to pursue and how to approach them. Companies like Grafana figured this out years ago—they built intelligent pipelines by mining their open source usage data.
Grafana's approach is particularly clever. Their enterprise team monitors their open source community to spot organizations that might be ready for an enterprise proof of concept. They classify leads who've used the open source offering (whether testing, development, or production) as "pre-buyers" and those with no prior exposure as "pre-believers." That distinction alone changes how they sell.
The timing puzzle
Mining open source data for enterprise sales sounds straightforward until you actually try it. Three challenges make this genuinely hard:
Finding accounts worth pursuing. Not every developer interaction with your GitHub repository signals real buying intent—and many interactions aren’t even visible in the first place. Package installs via npm are anonymous, which makes creative data collection the first real challenge. Even when attribution is possible, enrichment based on GitHub accounts often introduces false positives, as many developers rely on burner emails or loosely maintained profiles.
Knowing when to engage. Developer activity happens on its own timeline. Reach out too early and the buyer hasn't felt enough pain yet—they're not ready to talk business. Wait too long and they've customized the open source version to fit their needs perfectly. That sweet spot in the middle? It's narrow.
Catching every signal. As developers increasingly rely on AI to generate code, traditional signals have become far scarcer. Fewer questions show up on Stack Overflow or Discord, deep dives into documentation happen less often, and meaningful feedback is harder to capture. At the same time, social platforms are flooded with AI-generated noise, making it increasingly difficult to separate genuine developer intent from synthetic activity.
Where to find developer intent
The core challenge is separating real revenue signals from noise. Before you can do that, you need to understand where developer intent actually shows up and how to attribute that activity to a real organization.
My entire pipeline is built around a set of scripts that run either on a schedule or fully automated, continuously refreshing signals and pushing structured intent data into the CRM.
The intent sources that matter
For open-source companies, I focus on a small number of high-leverage sources.
GitHub engagement/ activity Most teams look at stars, watchers, forks, issues, pull requests, or the Code Search API. The GitHub API makes it relatively easy to assemble developer lists across these dimensions. However, the critical next step is often missed: cloning repositories and verifying concrete artifacts that prove a dependency is still actively used. This distinction—historical interest vs. active usage—is essential, and I’ll break it down further below.
Package manager usage There are two common approaches here. The first is analyzing GitHub’s dependency graph to identify downstream dependents. The second is attaching usage tracking directly to a package (for example, via npm telemetry) and storing events in a database. The latter is far more invasive and significantly less common—or publicly accepted.
Documentation and technical content Documentation is a strong signal, but it’s becoming harder with the rise of AI. Increasingly, docs are consumed by AI systems rather than developers directly, which makes attribution via IP-to-company mapping unreliable. That said, not all doc interactions are equal: someone deep in API references signals far higher intent than someone skimming a landing page. Time spent still matters.
Product trials Trial behavior—API calls, data usage, feature exploration, or similar metrics—is one of the strongest signals available. It becomes even more compelling when multiple developers from the same organization are active during the trial window.
Not all signals should be treated equally. I use weighted scoring models to triangulate intent across sources. A GitHub star is weaker than a fork. A fork is weaker than an issue. An issue is weaker than sustained trial usage. The goal is to combine these signals into a coherent picture of real buying intent.
The activity problem
The identity problem
Here's where things get messy. Seeing developer activity is one thing. Knowing which company that developer works for is entirely different.
Decoding GitHub identities
Some developers make it easy—they disclose their employer in their public profile, include their work email, or link to LinkedIn. But most don't. Here's how I piece together the puzzle:
Public profile mining. Start with what's visible: GitHub ID, display name, profile pic. Cross-reference this against LinkedIn and other professional networks. It takes some clever searching, but you'd be surprised how often you can connect the dots.
Data enrichment tools. Services like Clearbit can fill in gaps once you have a starting handle—GitHub ID, Twitter, LinkedIn, whatever. One piece of the puzzle often unlocks the others.
Your own CRM. If you ask for GitHub IDs during signup (for trials, webinars, community access), you might already have the answer sitting in your database. Cross-reference active GitHub contributors against your existing contacts.
Custom tooling. This is where I've spent the most time. I've built tooling for customers that combines all of the above with strong computing and search capabilities. It's not magic, but it scales what would otherwise be impossible manual work.
Decoding package manager identities
Custom gateways. If you want to track which organizations are downloading your packages, you can create a command that routes through a gateway capturing the downloader's IP. Reverse IP lookup tools like Leadfeeder or MaxMind can then identify the organization.
Telemetry. Many OSS projects now embed opt-in telemetry for product feedback. Common data includes IP addresses, whether instances are active, software versions, and timestamps. If you can link this to known developers, you unlock which accounts are actively using your code.
Decoding docs and trial identities
This is actually the easier part if you're already tracking first-party data. Marketing tools like HubSpot track user cookies across website activity and link it to identity when someone submits a form. The challenge is filtering who's spending time on high-intent pages (implementation guides, pricing, enterprise features) versus low-intent browsing (blog posts, about page).
For trials, product analytics tools like Amplitude or Mixpanel connect first-party data to usage patterns. If someone's signed up, you know who they are and exactly what they're doing with your product.
From signals to sales intelligence
At this point, you should have a picture emerging: which developers from which accounts are showing medium-to-strong intent signals. The question now is what to do with it.
Is an account in "nurture mode" where you should focus on education and evangelism? Or have they reached the point where it's time to activate sales, reach decision-makers, and leverage your developer champions to close the deal?
Account scoring based on developer activity
Account scoring helps you understand which accounts are cold, warm, or hot. You're essentially assigning numerical values to intent activities and weighting different signal types to see which accounts show surges (or slowdowns) in activity.
The frameworks you'll find from Hubspot and others work here—you're just applying them to developer-specific signals rather than traditional marketing touches.
Mapping scores to your funnel
Developer tooling companies usually run hybrid bottom-up and top-down GTM motions. One useful approach: plot a matrix with your top-down funnel stages (Prospect, Lead, Opportunity, Customer) on one axis and your bottom-up activity scores (Low to High) on the other.
When you map accounts to this matrix, patterns emerge. A high-activity account still in the Prospect stage? That's an opportunity being missed. A Customer with declining activity? Potential churn risk.
Building activity timelines
Going deeper into individual accounts, I track developer activities across time. Two views help:
Velocity view. Graph the account score over time. This shows you in real-time when an account is heating up and when interest is cooling.
Activity view. Map specific developer activities chronologically. You can build qualification criteria here—something like "1 GitHub activity + 1 package manager install + 5 key doc pages = Qualified"—to identify where to focus.
The bottom line
Mining open source data for enterprise sales isn't simple. It demands thinking carefully about which intent sources matter, figuring out how to decode identities from anonymous developer activity, and building systems to derive actionable account intelligence.
But for commercial open source businesses, the payoff is enormous. You're not guessing which accounts to target—you're watching real developers with real business needs engage with your product. That's the kind of insight that transforms enterprise sales from cold outreach into warm conversations with people who already know and trust what you've built.
The developers are already there. The question is whether you're paying attention.
For overview, I added an image of the entire flow I did with OpenQ to showcase all aspects:
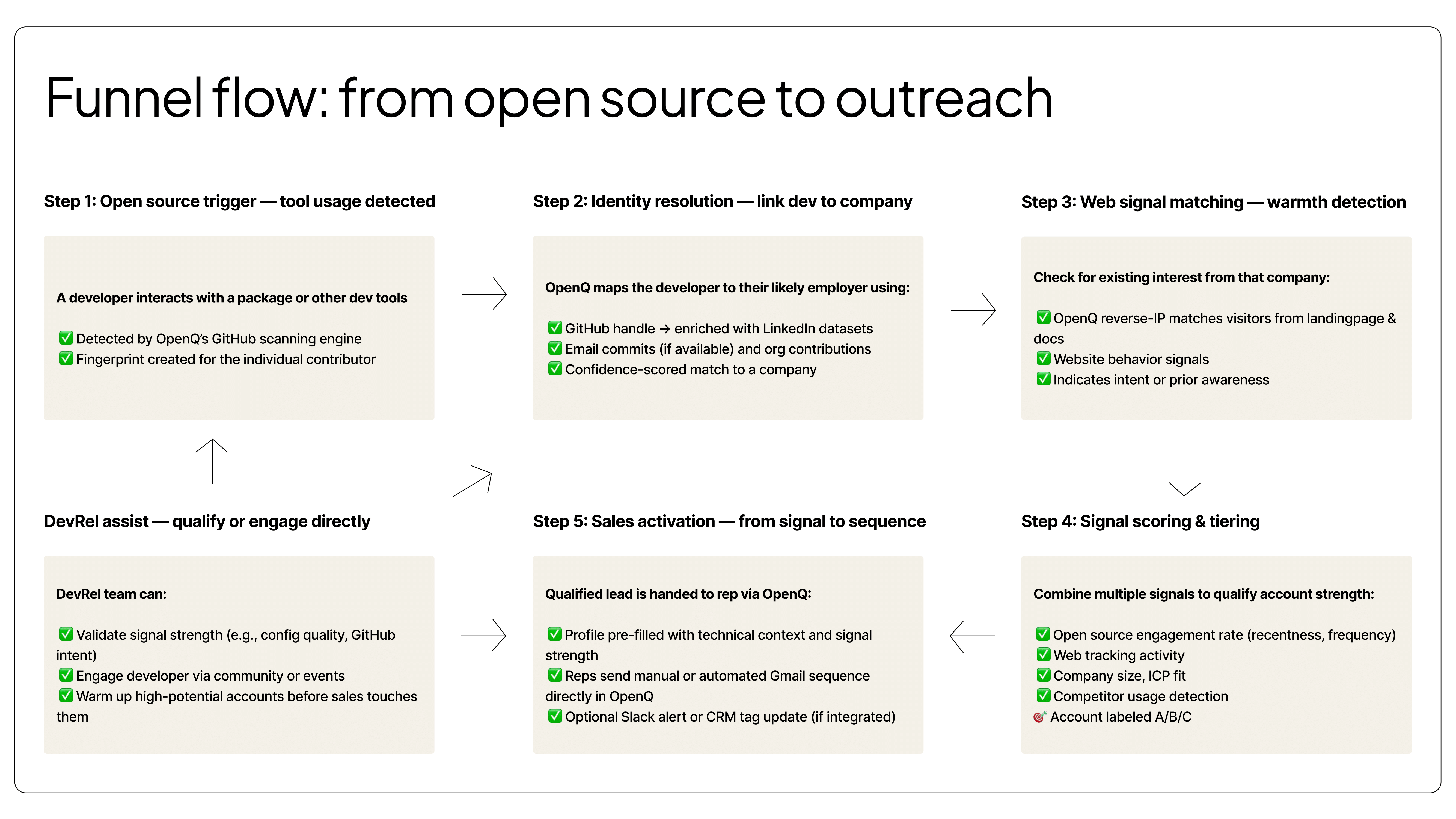
Important to mention at OpenQ we built an entire all-in-one process. I think nowadays with vibecoding and effective scripting you can plug things together quite effectively yourself based on the data points you find relevant. Then you can decide how deep you want to score everything and just plug it into your CRM.